Free
$0Free plan available.
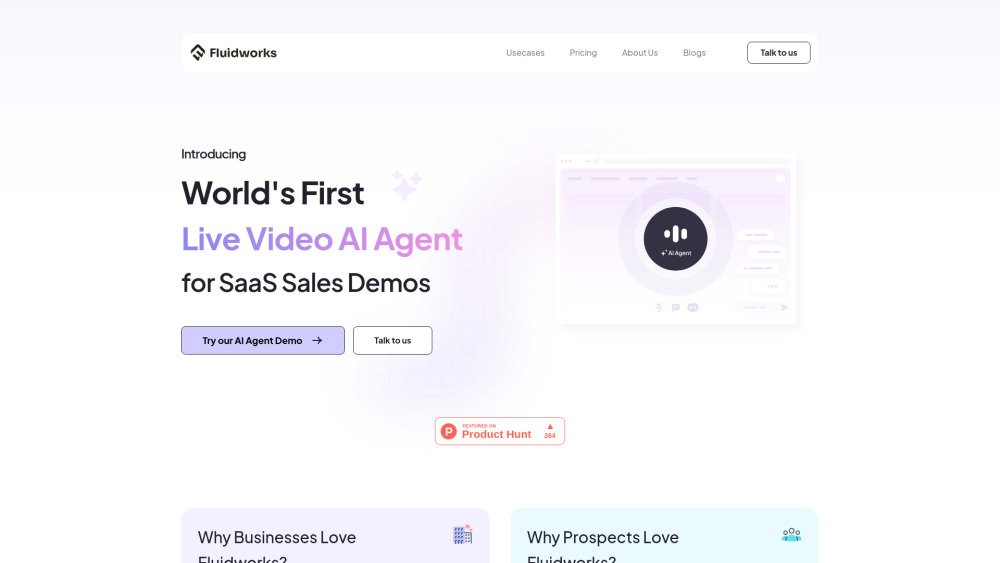
Fluidworks provides an AI agent capable of conducting live video calls, delivering personalized product demos, and guiding prospects through the sales funnel. Designed to convert signups into customers within 90 seconds, it features voice-guided, hands-free onboarding. Fluidworks is built for SaaS companies aiming to double activation rates without increasing their customer support headcount, offering interactive onboarding that communicates, demonstrates, and drives conversions.
The Fluidworks AI agent learns your software by analyzing your sales demos, tutorials, documentation, and feedback calls with SDRs. It then automates interactive, live product demos and onboarding processes to save pre-sales resources.
The AI agent learns your software by analyzing your sales demos, tutorials, documentation, and feedback calls with SDRs.
Fluidworks helps accelerate user activation, personalize the onboarding experience, increase paid conversions, and provide 24/7 in-app guidance.
Fluidworks can be used for customer onboarding to guide new users through a personalized experience and for employee training to train staff more quickly and effectively.
Free plan available.
Use these comparison pages to understand the trade-offs between the models most relevant to Fluidworks.
Compare Gemini 1.0 Pro Deprecated and Gemini 2.0 Flash across pricing, context window, capabilities, benchmarks, and API access to choose the better fit for long-context workloads versus long-context workloads.
Compare Gemini 1.0 Pro Deprecated and Gemini 2.5 Flash across pricing, context window, capabilities, benchmarks, and API access to choose the better fit for long-context workloads versus long-context workloads.
Compare Gemini 2.0 Flash Lite and Gemini 2.0 Flash across pricing, context window, capabilities, benchmarks, and API access to choose the better fit for long-context workloads versus long-context workloads.
Compare Gemini 2.5 Flash and Gemini 2.0 Flash across pricing, context window, capabilities, benchmarks, and API access to choose the better fit for long-context workloads versus long-context workloads.