
1. Anthropic raises $65B Series H at a $965B valuation to fund AI safety and expansion
Anthropic said in an official X post: Anthropic raises $65B Series H at a $965B valuation to fund AI safety and expansion. Anthropic is converting enterprise demand and fresh capital into a larger push around Claude capacity, safety research, and platform expansion. The company is entering a scale-up stage where revenue quality, compute capacity, and model reliability will matter as much as headline valuation.
Aitoolsfi Summary:Capital scale: Anthropic is entering a capital-heavy phase where model progress depends on compute, talent, and global enterprise expansion.
Safety funding: The round is framed around advancing AI safety and research, tying financing directly to frontier-model operating costs.
Enterprise pressure: A near-trillion-dollar valuation raises the bar for Claude adoption, revenue quality, and durable platform demand.
Source: Anthropic
2. Anthropic introduces Claude Opus 4.8 with sharper judgment and longer independent work
Anthropic said in an official X post: Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors. Claude Opus 4.8 is being positioned around steadier judgment, lower hallucination, longer work sessions, and better agent coordination rather than a single flashy benchmark. The Claude ecosystem is moving toward enterprise-grade agent loops where reliability, steering, and subagent orchestration define product value.

Aitoolsfi Summary:Judgment focus: The Claude Opus 4.8 launch emphasizes steadier judgment and self-assessment over a purely headline-driven capability jump.
Longer work: Longer independent work sessions are important for agent tasks that require planning, checking, and iteration.
Platform maturity: The release pushes Claude closer to enterprise use cases where consistency matters more than isolated impressive outputs.
Source: Anthropic
3. Anthropic run-rate revenue reaches $47B after rapid enterprise adoption
Simon Willison reports: Anthropic run-rate revenue reaches $47B after rapid enterprise adoption. Anthropic's reported run-rate growth links the funding story to enterprise adoption rather than valuation alone. The business test is whether Claude revenue can keep scaling while compute, support, and reliability costs rise.
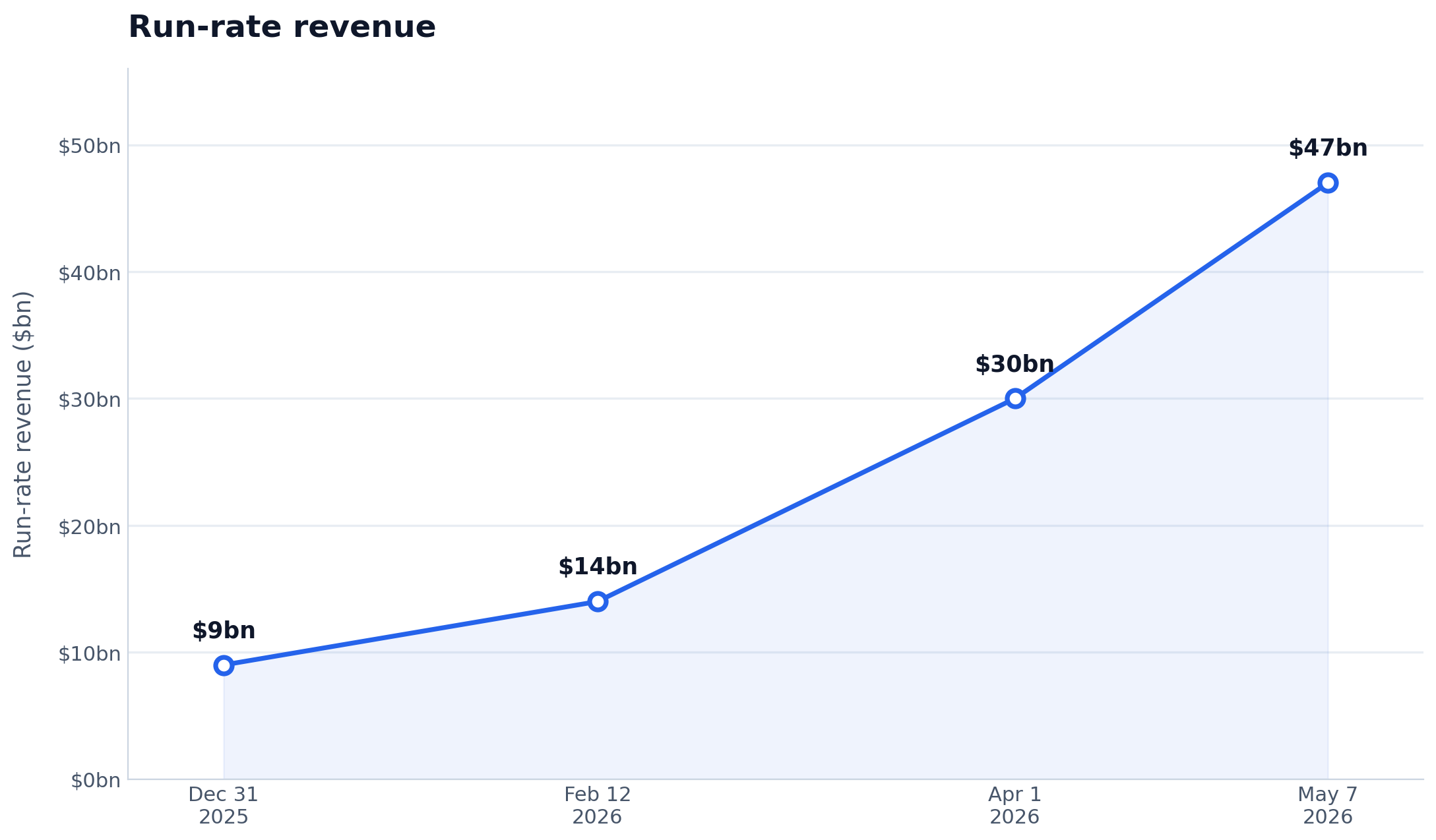
Aitoolsfi Summary:Revenue acceleration: Anthropic's reported run-rate growth shows Claude demand is moving from experimentation into paid enterprise usage.
Adoption signal: The revenue figure matters because it links the funding story to customer traction rather than valuation alone.
Scale test: The next challenge is whether rapid adoption can keep pace with compute cost, support needs, and model reliability expectations.
Source: Simon Willison
4. Anthropic ships Claude Opus 4.8 with lower hallucination rates and mid-conversation system messages
Simon Willison reports: Anthropic ships Claude Opus 4.8 with lower hallucination rates and mid-conversation system messages. Claude Opus 4.8 is being positioned around steadier judgment, lower hallucination, longer work sessions, and better agent coordination rather than a single flashy benchmark. The Claude ecosystem is moving toward enterprise-grade agent loops where reliability, steering, and subagent orchestration define product value.

Aitoolsfi Summary:Reliability upgrade: Claude Opus 4.8 is being positioned around more dependable answers, not only higher benchmark scores.
Runtime steering: Mid-conversation system messages give developers more control over long sessions and agent behavior as context changes.
Agent fit: Lower hallucination and better steering make the model more useful for enterprise workflows that need sustained, auditable execution.
Source: Simon Willison
5. llm-anthropic 0.25.1 adds Claude Opus 4.8 and a fast-mode option for enabled accounts
Simon Willison reports: llm-anthropic 0.25.1 adds Claude Opus 4.8 and a fast-mode option for enabled accounts. Claude Opus 4.8 is being positioned around steadier judgment, lower hallucination, longer work sessions, and better agent coordination rather than a single flashy benchmark. The Claude ecosystem is moving toward enterprise-grade agent loops where reliability, steering, and subagent orchestration define product value.
Aitoolsfi Summary:Tooling update: llm-anthropic support brings Claude Opus 4.8 into a practical developer interface instead of leaving it as a model announcement.
Speed option: Fast mode gives eligible accounts a performance lever for workflows where latency matters more than maximal reasoning depth.
Developer reach: CLI and library support can accelerate testing because developers can plug the model into existing scripts and local workflows.
Source: Simon Willison
6. Anthropic ships Claude Opus 4.8 with benchmark gains over GPT-5.5 and Gemini 3.1 Pro
The Decoder reports: Anthropic releases Claude Opus 4.8, which beats GPT-5.5 and Gemini 3.1 Pro in most benchmarks. The model also catches its own coding errors four times more often than its predecessor. Claude Opus 4.8 is being positioned around steadier judgment, lower hallucination, longer work sessions, and better agent coordination rather than a single flashy benchmark. The Claude ecosystem is moving toward enterprise-grade agent loops where reliability, steering, and subagent orchestration define product value.

Aitoolsfi Summary:Benchmark challenge: Claude Opus 4.8 is being judged directly against rival frontier models, making comparative performance part of the launch story.
Coding accuracy: The reported improvement in catching coding errors points to practical gains for software-agent use cases.
Model race: The result keeps pressure on OpenAI, Google, and Anthropic to prove model quality through repeatable task performance.
Source: The Decoder
7. Anthropic adds Dynamic Workflows to Claude Opus 4.8 for coordinating subagents
TechCrunch reports: The new Opus model comes with a tool called Dynamic Workflows, for coordinating swarms of subagents. Claude Opus 4.8 is being positioned around steadier judgment, lower hallucination, longer work sessions, and better agent coordination rather than a single flashy benchmark. The Claude ecosystem is moving toward enterprise-grade agent loops where reliability, steering, and subagent orchestration define product value.

Aitoolsfi Summary:Subagent orchestration: Dynamic Workflows turns Claude Opus 4.8 into a coordination layer for multi-step agent work.
Workflow structure: The feature matters because complex tasks increasingly require delegation, progress tracking, and role separation across agents.
Enterprise automation: If reliable, subagent coordination can make Claude more attractive for business processes that are too large for a single prompt loop.
Source: TechCrunch
8. Illinois passes AI safety testing law backed by Anthropic and OpenAI
Ars Technica reports: Here’s why Anthropic and OpenAI are on board with Illinois safety testing. AI safety testing is becoming part of the policy layer around frontier model deployment, with major labs supporting more formal evaluation requirements. Governance pressure is shifting from abstract AI risk debates toward concrete testing obligations before models reach broader deployment.

Aitoolsfi Summary:Testing mandate: Illinois is turning AI safety testing into a concrete regulatory requirement rather than a voluntary best practice.
Lab alignment: Support from Anthropic and OpenAI suggests major labs may prefer clearer state-level testing rules over regulatory uncertainty.
Governance baseline: The law points to a future where frontier model launches face more formal evaluation expectations before broad deployment.
Source: Ars Technica
Summary
Anthropic shows a market moving past novelty and into operational pressure. The most important AI updates now sit around deployment boundaries: who can access a model, which tools an agent can call, how performance is measured in real tasks, and whether the business case is strong enough to justify production use.